





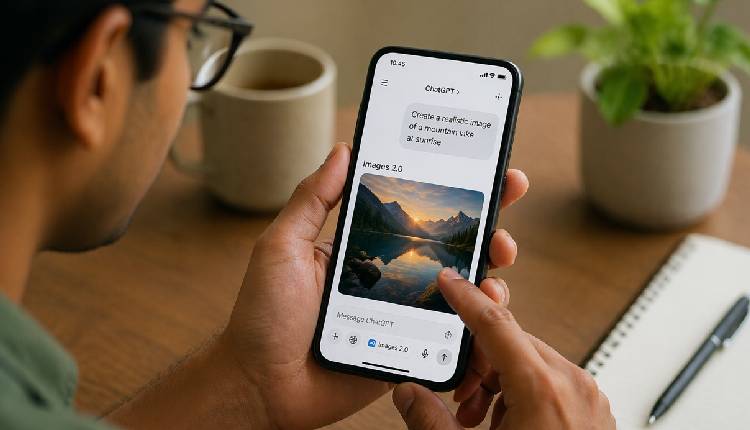
New Delhi: ChatGPT parent OpenAI has rolled out ‘Images 2.0’, its next-generation image generation model, aimed at delivering more precise, realistic and usable visuals with advanced reasoning capabilities.
The new model is a significant improvement in following detailed instructions, accurately placing objects, and rendering complex elements such as dense text, user interfaces and multilingual content. It supports flexible aspect ratios and can generate images tailored for formats ranging from social media graphics to presentations, the company said in a statement.
A major upgrade is the integration of ‘thinking’ capabilities. When enabled, the model can use web search for real-time information, generate multiple distinct images from a single prompt, and verify outputs for accuracy and consistency.
According to the company, the update allows users to move from concept to finished visual assets with less manual effort.
Moreover, the model shows improved performance across languages, with stronger rendering of non-Latin scripts, including Hindi, Japanese, Chinese, Korean and Bengali, which makes it more useful for global users.
In terms of visual quality, Images 2.0 offers enhanced realism and stylistic accuracy across formats such as photographs, cinematic stills, manga and pixel art, with better handling of lighting, textures and fine details, it added.
The company also highlighted a wide range of use cases and styles such as UI screenshots, magazine layouts, infographics, handwritten notes, comics and manga, advertisements, and cinematic visuals, as well as design workflows across platforms such as Canva, Figma and Adobe.
In addition, developers can access the model via the ‘gpt-image-2’ API, enabling integration into products for use cases such as design, marketing, education and content creation.
The tool is also available within ChatGPT and Codex platforms, OpenAI said.
However, the company noted that while the model represents a major step forward, it still faces limitations in rendering highly complex spatial tasks or extremely detailed repetitive patterns, and outputs such as diagrams may require human review.
OpenAI also flagged that it has implemented multiple safety layers, including prompt- and image-level checks, to prevent harmful or misleading content, alongside provenance tools such as metadata tagging and watermarking.
The new version of the image model is available, with advanced features accessible to paid users. The company also said the ‘gpt-image-2’ model can be access via the API, with pricing varying depending on the selected image quality and resolution.
(IANS)











{kind=link}